

DeepSeek distillation allegations expose a new frontier in China IP theft. Learn how AI model distillation works, what OpenAI found, and how to protect your AI assets.
When NVIDIA lost $589 billion in market value in a single trading day after DeepSeek’s January 2025 launch, the AI industry didn’t just experience a stock correction. It confronted a question that has since escalated into a geopolitical IP dispute: how did a Chinese lab achieve frontier-level reasoning capabilities at roughly one-tenth the compute cost of its American rivals? The answer, according to OpenAI and Anthropic, involves DeepSeek distillation, a technique that may have used proprietary U.S. AI model outputs as unauthorized training data, potentially replicating years of R&D investment without permission.
Key Takeaways
- DeepSeek’s R1 distill models were trained using a teacher-student technique that transfers reasoning capabilities from a large model to a smaller one — and OpenAI alleges its own models were used as unauthorized teachers.
- OpenAI found that DeepSeek’s outputs were 74.2% similar in writing style to ChatGPT’s, and detected suspicious API access through obfuscated third-party routers designed to evade detection.
- Anthropic independently confirmed that DeepSeek and at least two other Chinese AI labs made over 16 million queries to Claude using approximately 24,000 fake accounts to harvest training data.
- China theft of intellectual property costs the U.S. economy between $225 billion and $600 billion annually, and AI model extraction has become a primary vector alongside traditional trade secret theft.
- If your company’s AI model is accessible via API, you likely have distillation exposure you haven’t yet quantified — and the legal framework to address it is still being written.
What Is DeepSeek Distillation and Why Is It at the Center of a Global IP Dispute
Knowledge distillation is an AI training technique in which a large, highly capable model — called the “teacher” — generates outputs, and a smaller model — called the “student” — is trained to replicate those outputs rather than learning from raw data. Think of it like this: instead of teaching a student to solve math problems from a textbook, you hand them a stack of worked solutions from an expert tutor and have them learn the tutor’s reasoning patterns directly. The student doesn’t need to reinvent the tutor’s years of expertise — it inherits them.
DeepSeek applied this technique to build its publicly released DeepSeek R1 distill model family. The controversy is not that DeepSeek used distillation. The controversy is whose model served as the teacher.
If your company’s AI model outputs are being used to train a competitor’s system, you may have IP exposure you haven’t yet quantified — and the DeepSeek case is the reason that exposure is no longer theoretical.
How the Teacher-Model and Student-Model Process Actually Works
The distillation pipeline has a straightforward structure that relies on artificial intelligence to transfer learned capabilities efficiently. A large, capable teacher model generates outputs — particularly chain-of-thought reasoning traces that show how it works through complex problems. These smaller models are then trained on those outputs, learning to reproduce the teacher’s reasoning patterns without ever accessing the teacher’s underlying code, weights, or architecture.
This is entirely legitimate when a company distills its own models. OpenAI, Anthropic, and Google all use internal distillation to create efficient, deployable versions of their frontier systems. The legal and ethical problem arises when a company uses another company’s model as the teacher without authorization.
According to Anthropic’s published research, a distillation attack involves using a rival lab’s AI to generate massive volumes of training data — outputs that capture the teacher model’s reasoning capabilities — and then using that data to train a student model that inherits those capabilities. The result: the student model achieves performance that would otherwise require either access to the teacher’s proprietary weights or years of independent R&D.
DeepSeek claimed its model was trained for approximately $5.6 million, according to AP News reporting, achieving better performance than many expected at that price point. Training a frontier model from scratch comparable to GPT-4 is estimated to cost tens of millions of dollars. Winston & Strawn’s published analysis noted that DeepSeek used roughly one-tenth the computing power OpenAI did — a gap that DeepSeek knowledge distillation from a capable teacher model would help explain. Martin Vechev of INSAIT has argued that even the $5.6M figure is misleading, since it accounts for only a single training run and omits prior research costs, according to The Recursive.
Critically, distillation does not require access to a model’s weights — only its outputs. That makes unauthorized distillation significantly harder to detect and prevent, because the attack surface is the same public API that any paying customer can access.
DeepSeek’s Published Model Family and What the Names Reveal
The naming convention of DeepSeek’s distilled models is itself informative. Each name in the DeepSeek R1 distill models series encodes three pieces of information: the teacher model (DeepSeek-R1), the student architecture (Qwen or LLaMA), and the parameter count (7B, 14B, 32B, or 70B). Parameter count is the primary technical signal about a model’s capability tier and the compute required to run it.
The DeepSeek R1 distill models released publicly in early 2025 include four primary variants:
| Model | Student Architecture | Parameters |
| DeepSeek-R1-Distill-Qwen-7B | Alibaba Qwen | 7 billion |
| DeepSeek-R1-Distill-Qwen-14B | Alibaba Qwen | 14 billion |
| DeepSeek-R1-Distill-Qwen-32B | Alibaba Qwen | 32 billion |
| DeepSeek-R1-Distill-LLaMA-70B | Meta LLaMA | 70 billion |
According to DeepSeek’s model card on HuggingFace, the distilled models were fine-tuned on approximately 800,000 samples generated by the deepseek r1 teacher, with context windows extending up to 32,000 tokens for handling long inputs.
The deepseek r1 distill qwen line uses Alibaba’s Qwen architecture as the student framework across the 7B, 14B, and 32B sizes. deepseek r1 distill qwen 7b is the smallest and most accessible variant, optimized for deployment on consumer hardware. deepseek r1 distill qwen 14b sits in the mid-tier, offering a balance between performance and compute cost. DeepSeek R1 distill Qwen 32B is the largest Qwen-based variant and, according to NVIDIA’s published model card, outperforms OpenAI-o1-mini across various benchmarks — a result that implies the student model successfully inherited high-level reasoning capabilities from its teacher. deepseek r1 distill llama 70b uses Meta’s LLaMA architecture scaled to 70 billion parameters, making it the most capable and compute-intensive of the distilled variants.
The public release of these DeepSeek R1 distill models on HuggingFace means that any proprietary insights embedded in those outputs — whether derived from DeepSeek’s own R1 model or, as alleged, from OpenAI’s systems — have already propagated globally through open-source distribution channels. The alleged IP extraction, if confirmed, cannot be recalled.
DeepSeek Knowledge Distillation and DeepSeek Model Distillation: What Distinguishes the Process
DeepSeek knowledge distillation refers specifically to the transfer of reasoning capabilities from the large R1 teacher to smaller student architectures through synthetic training data. DeepSeek model distillation, used more broadly, describes the overall process of producing compressed, deployable models from a high-performance parent.
What distinguishes DeepSeek’s approach from standard industry practice is the scale and systematic nature of the data generation process. While other U.S. frontier labs use internal distillation to compress their own systems, DeepSeek’s critics argue that its R1 teacher was itself built in part on outputs harvested from external models without authorization — meaning every downstream DeepSeek R1 distill Qwen and DeepSeek R1 distill LLaMA 70B variant may carry embedded IP extracted from U.S. competitors.
This distinction matters legally: if the teacher model’s training data was improperly obtained, the taint potentially propagates to every student model trained on its outputs, regardless of whether those student models were independently developed.
The DeepSeek Controversy That Put China’s AI Industry Under a Microscope
DeepSeek’s January 2025 launch was the most disruptive single event in AI since ChatGPT’s debut. Bloomberg reported that NVIDIA’s stock dropped approximately 17% in a single session, erasing $589 billion in market value — the largest single-day market cap loss in stock market history. The Nasdaq fell over 3% as investors concluded that U.S. AI companies’ competitive advantage might be less durable than their valuations implied.
The speed and cost-efficiency of DeepSeek’s achievement is precisely what made the distillation allegations credible to U.S. policymakers, not just rival companies. When a relatively unknown Chinese lab matches frontier-level performance at a claimed training cost of $5.6 million — a figure that U.S. labs spend on a fraction of a single large training run — the obvious question is how. The distillation hypothesis provided the most technically coherent answer.
House Speaker Mike Johnson addressed DeepSeek publicly on January 27, 2025, characterizing China’s AI advancement as a direct threat, according to Axios reporting. The U.S. House Select Committee on the Chinese Communist Party highlighted DeepSeek as a case study in unfair technology acquisition and pushed for tighter export controls in the weeks that followed. The business disruption DeepSeek caused meant that the IP allegations received immediate congressional and regulatory attention rather than being treated as a private commercial dispute.

OpenAI’s Specific Allegations and the Evidence It Cited
OpenAI’s allegations are specific and technically grounded. In late January 2025, OpenAI told Axios it had evidence of distillation attempts by China-based groups targeting its models. The company identified two distinct categories of evidence.
First, there was the output similarity data. One analysis found that DeepSeek’s answers were 74.2% similar in writing style to ChatGPT’s responses — a degree of similarity that is statistically difficult to explain without training on ChatGPT’s outputs, as Windows Central reported.
Second, there was the access trail. According to AP News, OpenAI detected an abnormal volume of API requests originating from what turned out to be obfuscated third-party routers — intermediary proxy services that masked the true origin of the queries. DeepSeek allegedly used thousands of burner API accounts routed through these obfuscated third party routers to harvest model outputs systematically, with rapid-fire complex queries across accounts that were too coordinated to represent ordinary user behavior. Microsoft, which hosts OpenAI’s models on Azure, collaborated in analyzing access logs and identified clusters of accounts engaging in this behavior.
The use of third party routers to mask the origin of API calls is an emerging evasion tactic that AI providers are now actively designing detection systems to counter.
U.S. Congressional and Regulatory Response to DeepSeek
Washington’s response to the DeepSeek controversy moved faster than most congressional action on AI. By February 2025, U.S. lawmakers introduced the “No DeepSeek on Government Devices Act,” which would ban DeepSeek’s application from all federal networks and devices, according to AP News. The U.S. House Select Committee on the Chinese Communist Party issued a formal report titled “DeepSeek Unmasked,” which characterized the lab’s rapid capability gains as evidence of systematic IP acquisition from other U.S. frontier labs. The House Chief Administrative Officer separately banned congressional staff from using DeepSeek, citing risks of malware and data exposure, as Axios reported.
Texas Governor Greg Abbott ordered DeepSeek banned from all state-issued devices effective January 31, 2025, according to AP News — making Texas the first state to take formal action.
In June 2025, a bipartisan bill was introduced to bar all Chinese AI systems from federal agency use, explicitly citing the DeepSeek incident as grounds, according to AP News. As of early 2026, the Justice Department had not filed a lawsuit against DeepSeek — enforcement against a Chinese firm operating primarily outside U.S. jurisdiction presents serious practical obstacles — but federal authorities indicated they were investigating potential trade secret and computer fraud violations.
Congressional scrutiny signals that AI distillation by foreign adversaries will likely become a formal export control issue, not just a civil IP matter between private companies.
How OpenAI Distillation Allegations Work as an IP Claim
The news narrative and the legal substance of the OpenAI distillation allegations are two different things, and conflating them creates strategic blind spots for founders trying to assess their own exposure. OpenAI’s allegations are credible as a factual matter. Whether they translate into actionable IP claims under existing law is a distinct and unresolved question.
Winston & Strawn’s published legal analysis identified multiple plausible legal theories: breach of contract through terms of service violation, misappropriation of trade secrets under the Defend Trade Secrets Act (DTSA), and copyright infringement in AI-generated outputs. Each theory has merit, and each has significant complications when the defendant is a Chinese company operating primarily outside U.S. jurisdiction.
A terms of service violation and an IP theft claim are legally distinct. The remedies, likelihood of success, and enforceability against a Chinese entity differ significantly across each theory.

How OpenAI’s IP Claim Against DeepSeek Works Across Three Legal Theories — Source: Winston & Strawn IP Analysis, 2025; OpenAI Terms of Use
Is DeepSeek Distillation from ChatGPT a Terms of Service Violation
The OpenAI terms of use contain explicit language prohibiting users from using outputs from OpenAI’s services to develop competing AI models. AP News confirmed that OpenAI’s official terms define exactly this process — knowledge distillation using one model’s answers to teach another — and prohibit it. This contractual prohibition is likely the most immediately available legal tool, but it operates as a breach of contract claim, not a statutory IP claim, and enforcement against a Chinese company raises serious jurisdictional complications.
Anthropic has parallel prohibitions in its terms of service. Its published research on detecting and preventing distillation attacks demonstrates that Anthropic treated these ToS provisions as enforceable and actively implemented technical detection mechanisms to support enforcement, monitoring for anomalous API usage patterns consistent with systematic harvesting.
If you are building any AI product using outputs from commercial AI APIs, review the provider’s terms of service now. The distillation prohibition is standard across major providers, and the enforceability window is narrowing as both technical detection and legal infrastructure mature.
Is AI Distillation Using Another Company’s Model Illegal Under U.S. Law
Separating the ToS breach from independent statutory violations requires working through three distinct legal frameworks, none of which provides a clean answer.
Copyright: The U.S. Copyright Office has issued guidance suggesting that AI-generated content may not be protectable without meaningful human authorship. If AI outputs lack copyright protection, a distillation claim based on copying those outputs loses its foundation. This remains an actively contested legal question. For more on how copyright intersects with AI-generated content, see our AI copyright resource.
Trade secrets: The DTSA provides a stronger potential basis if OpenAI can demonstrate that its model outputs reveal something about proprietary model weights, architecture, or training methodology that DeepSeek then used. The trade secret theory requires showing both that the information qualifies as a trade secret and that DeepSeek misappropriated it through improper means — which the obfuscated third-party router access pattern could support. Our overview of trade secret protection for software covers the foundational requirements.
Computer fraud: The unauthorized access to OpenAI’s systems through fake accounts and proxies potentially implicates the Computer Fraud and Abuse Act (CFAA) as well, independent of IP law.
The legal framework for AI distillation as IP theft does not yet exist as settled law. The first companies to litigate these claims will shape the rules for every AI firm that follows.
China Intellectual Property Theft and the Broader Pattern Behind the DeepSeek Allegations
The DeepSeek distillation allegations don’t exist in a vacuum. They are the latest development in a documented pattern of china theft of intellectual property targeting U.S. technology firms — a pattern that U.S. government agencies, trade groups, and academic researchers have been tracking for over a decade. Treating the DeepSeek controversy as an isolated incident produces the wrong risk assessment for any tech company evaluating its own exposure.
The Commission on the Theft of American Intellectual Property — an independent, bipartisan research body — estimates that China theft of intellectual property costs the U.S. economy between $225 billion and $600 billion annually, a figure that FBI Director Christopher Wray has cited publicly in congressional testimony as defining the scale of the problem, as CBS News reported. The FBI currently has over 2,000 active investigations tied to Chinese economic espionage, with a new case opened roughly every 10 hours, according to Director Wray’s public statements reported by Axios and Nextgov.
The shift toward AI-specific IP targeting means software founders and AI companies — not just defense contractors and manufacturers — are now primary targets.
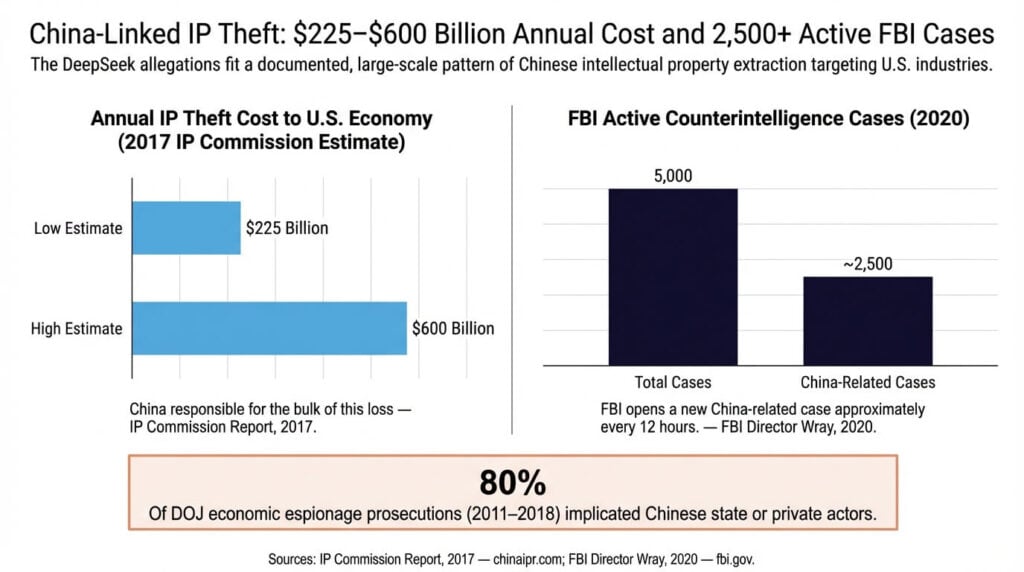
China Intellectual Property Theft Statistics That Define the Scale
The quantitative picture of China and intellectual property theft is significant enough that it warrants precise attribution rather than summary. The IP Commission’s figures — $225 billion on the low end, $600 billion on the high end annually — represent direct economic losses from counterfeit goods, pirated software, and theft of trade secrets. The FBI’s reported caseload includes hundreds of prosecutions specifically for trade secret theft with a China nexus over the past five years.
What has changed in recent years is the target profile. CISA advisories have increasingly flagged AI-specific IP theft vectors, including API abuse, model extraction attacks, and what the agency describes as software supply chain compromise designed to exfiltrate training data. China’s theft of intellectual property has shifted from physical espionage and manufacturing trade secrets toward the software and AI layer — precisely the layer where most tech startups are building.
The combination of high-value targets (AI models representing years of R&D), low detection risk (API access leaves limited forensic evidence), and jurisdictional immunity (Chinese firms face limited U.S. legal exposure) makes AI distillation an unusually attractive IP acquisition strategy. For a broader look at how IP theft affects technology companies, see our AI patent strategy guide.
How China’s Approach to Intellectual Property Theft Has Evolved Toward AI
The evolution from physical espionage to API-layer extraction reflects a rational adaptation to changing circumstances. U.S. export controls on advanced AI chips — the Bureau of Industry and Security (BIS) rules issued in October 2022 and expanded in October 2023 — restricted Chinese firms’ access to the NVIDIA hardware needed to train frontier models from scratch. Smuggling of restricted chips has been reported, but the volumes are insufficient to close the capability gap through hardware alone.
The alternative is software-layer IP extraction: if you cannot acquire the compute to train a frontier model, you extract the frontier model’s knowledge through its public API and use distillation to embed that knowledge in a model you can train on accessible hardware. This logic explains why distillation-based attacks are particularly attractive as an IP acquisition strategy directed at other U.S. frontier labs — they require no physical access, leave limited forensic evidence, and are difficult to prosecute across jurisdictions.
Export controls on hardware are creating a substitute demand for software-layer IP extraction, a risk that no existing export control framework currently addresses directly.
How Anthropic, OpenAI and Other U.S. Frontier Labs Are Detecting and Preventing Distillation Attacks
The most technically substantive response to distillation attacks came from Anthropic, which published detailed research titled “Detecting and Preventing Distillation Attacks” — naming DeepSeek, Moonshot AI, and MiniMax as entities it investigated. Anthropic’s findings are striking: the three Chinese labs collectively made over 16 million queries to Claude using approximately 24,000 fake user accounts, according to the published research. The scale of coordinated API access, the use of fake accounts to distribute queries and evade detection, and the systematic nature of the querying patterns all pointed to organized distillation campaigns rather than ordinary usage.
Anthropic’s detection methodology relied on multiple signals: anomalous query volume from specific IP ranges, statistical analysis of query content for patterns inconsistent with genuine user behavior, and analysis of the outputs of publicly released models for statistical fingerprints of specific training data. This last technique — sometimes called “membership inference” — can identify whether a particular dataset was used in training a model even without access to the model’s weights.
If you are licensing AI capabilities via API to third parties, implementing output monitoring and anomaly detection is no longer optional — it is a baseline IP protection measure.

How Obfuscated Third-Party Routers Enable Unauthorized Model Access
Obfuscated third-party routers are proxy services that route API requests through intermediate accounts or servers, masking the true origin of the requests. A user in a restricted region — or a user who has been banned following terms of service enforcement — can continue accessing an AI API by routing their queries through an intermediary service that presents a different identity to the API provider.
In the context of distillation attacks, these obfuscated third-party routers serve two functions. First, they allow access to continue after a specific account has been flagged and terminated. Second, they distribute query volume across many apparent sources, reducing the per-account query rate that would otherwise trigger anomaly detection systems based on usage thresholds.
The intermediary structure also complicates legal attribution: when a violation is detected, the chain of proxy services between the actual requester and the API endpoint creates evidentiary challenges. Microsoft Azure’s detection of the suspicious access reportedly required analysis of aggregate patterns across accounts rather than identification of any single bad actor.
AI API providers are now treating anomalous routing patterns as a primary security signal — and companies building on top of AI APIs should understand that their downstream use monitoring obligations may increase as a result.
What U.S. AI Companies Are Doing to Protect Their Models From Distillation
The technical countermeasures being deployed by U.S. frontier labs fall into several categories. Output watermarking embeds statistical signals in model outputs that survive into a student model trained on those outputs, allowing labs to identify their training data in a competitor’s released model. Rate limiting and behavioral anomaly detection flag accounts with usage patterns inconsistent with genuine applications. API key monitoring identifies clusters of accounts with correlated behavior suggesting coordinated access.
Anthropic has been particularly transparent in publishing its methodology, both to inform the research community and to signal to potential attackers that detection is possible, helping ai services industry-wide raise their defenses. OpenAI has focused more on enforcement — account termination, public advocacy for regulatory action — and on working with Microsoft to improve upstream detection through Azure’s access monitoring.
The fundamental asymmetry remains: distillation attacks require only public API access, while effective defense requires detecting patterns across billions of queries. No technical defense is perfect. The AI industry’s push for regulatory intervention — including the congressional proposals described earlier — reflects the recognition that this is a problem requiring legal infrastructure, not just better engineering.
Technical defenses alone are insufficient. The AI industry’s push for regulatory intervention reflects the recognition that this is a problem requiring legal infrastructure, not just engineering.
What the DeepSeek IP Dispute Means for Tech Startups and AI Founders
The DeepSeek controversy is not just a story about large AI labs and geopolitical rivalry. It has direct implications for every SaaS founder and tech startup building on or alongside AI models — and the implications are more immediate than most founders realize.
The DeepSeek case demonstrated that a capable adversary with API access to a frontier model can replicate years of R&D investment in months, not years. That timeline compression applies whether the adversary is a Chinese state-linked lab or a better-funded competitor with different ethical constraints. For startups, whose core asset is often a proprietary model trained on unique data or fine-tuned with proprietary techniques, the distillation risk is existential if left unaddressed.
Investors are beginning to reflect this in due diligence. Post-DeepSeek, AI IP questions have become standard in VC term sheet conversations: what is the company’s model trained on, who has API access, and what protections prevent a competitor from extracting the model’s capabilities through systematic querying? If your startup’s core asset is a proprietary AI model, get a formal AI IP audit before your next funding round — investors are now asking specifically about distillation risk exposure.

Why Proprietary AI Models Need Patent and Trade Secret Protection Now
The DeepSeek controversy makes two primary IP mechanisms more urgent for AI companies: patents and trade secrets. They serve different functions and are not mutually exclusive.
Patent protection requires public disclosure of the innovation in exchange for a time-limited exclusive right to practice it. For AI companies, patents are most valuable for novel architectural innovations, training methodologies, and application-specific implementations that can be described with sufficient specificity. USPTO data on AI-related patent filings shows consistent year-over-year growth in AI patent applications, reflecting the industry’s recognition that these protections matter. For a deeper look at what qualifies, see our guide to AI patent eligibility.
Trade secret protection requires no disclosure — only active, documented measures to maintain secrecy. For AI models, the combination strategy is becoming standard practice: patent the novel architectural innovations publicly while protecting training data composition, fine-tuning techniques, and model weights as trade secrets. This layered approach means that even if a competitor successfully distills your model’s outputs, they cannot reverse-engineer your training data or the specific techniques that produced your model’s unique capabilities.
A trade secret policy that documents your model development process and restricts access to training data and weights is the minimum protection any AI company should have in place. File patents for your novel innovations on top of that foundation. Our software patent guide covers how these two strategies interact in practice.
How the DeepSeek Case Should Change Your IP Strategy as a Founder
Three concrete actions emerge from the DeepSeek controversy for founders building AI products.
First, audit your terms of service if you offer AI APIs to third parties. If your terms don’t explicitly prohibit using your model’s outputs to train competing AI systems, update them immediately. The distillation prohibition is now standard practice across major AI providers, and the absence of such language leaves you without a contractual basis for enforcement.
Second, implement output monitoring if you license AI capabilities to third parties. Anomaly detection for API usage — flagging accounts with query patterns inconsistent with genuine application use — is now a baseline security measure, not an advanced capability. The Anthropic research demonstrates that coordinated distillation campaigns are detectable before they complete.
Third, consult with a patent attorney to evaluate whether your model architecture or training methodology contains patentable innovations before a competitor files first. A provisional patent application preserves your filing date for 12 months at a fraction of the cost of a full application, giving you time to evaluate the commercial value of the protection before committing to full prosecution. Learn more about the provisional patent process and how it applies to AI inventions.
The window to establish IP priority for AI innovations is compressing. The DeepSeek case demonstrates that capable competitors — including those targeting other U.S. frontier labs — can replicate frontier-level performance in months.
FAQ: DeepSeek Distillation and AI Intellectual Property
What is a DeepSeek distill?
A DeepSeek distill refers to a model in DeepSeek’s released family of AI models trained through DeepSeek knowledge distillation from the larger DeepSeek-R1 model. Rather than training from scratch on raw data, the DeepSeek R1 distill models — including DeepSeek R1 distill Qwen 7B, DeepSeek R1 distill Qwen 14B, DeepSeek R1 distill Qwen 32B, and DeepSeek R1 distill LLaMA 70B — were trained on approximately 800,000 output samples generated by the full R1 model, inheriting its reasoning capabilities in a smaller, more deployable package. The controversy arises because OpenAI alleges that the R1 model itself was trained using outputs harvested from OpenAI’s systems, meaning the distilled models may carry embedded IP extracted from a U.S. competitor without authorization.
Is AI distillation illegal?
Whether AI distillation is illegal depends entirely on what model’s outputs are used and under what conditions. Distilling your own model is entirely legal and is standard practice across the industry. The legal exposure arises when DeepSeek model distillation — or any model distillation — uses outputs from another company’s model without authorization, which can violate the model provider’s terms of service, potentially constitute misappropriation of trade secrets under the DTSA, and raise copyright claims to the extent AI outputs are protectable. No U.S. court has yet issued a definitive ruling on whether unauthorized distillation constitutes IP theft, making this an area of actively developing law.
What is the distillation process in DeepSeek?
DeepSeek’s distillation process used the deepseek r1 model as the teacher, generating large volumes of training data — particularly chain-of-thought reasoning traces — that were then used to train smaller student models built on Qwen and LLaMA architectures. According to DeepSeek’s published model card, approximately 800,000 samples were used to fine-tune the distilled variants, transferring the reasoning capabilities of the larger model into architectures that run on significantly less compute. The specific controversy regarding DeepSeek distillation from OpenAI involves allegations that DeepSeek used OpenAI model outputs — harvested through obfuscated third-party routers — as part of the training pipeline that produced the R1 teacher model.
Did DeepSeek use distillation from OpenAI models?
OpenAI has publicly alleged, and Anthropic’s independent research supports, that DeepSeek and other Chinese AI firms used distillation techniques on outputs from U.S. frontier models including OpenAI’s. OpenAI reported detecting access via obfuscated third-party routers — intermediary services that mask the true origin of API queries — used to harvest large volumes of model outputs for training. DeepSeek has not publicly confirmed this allegation. As of early 2026, no litigation has been filed, and enforcement against a Chinese company operating primarily outside U.S. jurisdiction remains a significant practical obstacle.
What does DeepSeek distill Qwen mean?
DeepSeek distill Qwen refers to distilled models that use Alibaba’s Qwen model family as the student architecture. The DeepSeek R1 distill Qwen series — available in 7B, 14B, and 32B parameter sizes — takes the Qwen base models and fine-tunes them on outputs generated by DeepSeek’s R1 reasoning model, effectively transferring R1’s reasoning capabilities into Qwen-architecture models. These are publicly available on HuggingFace and have been downloaded by developers globally, meaning any IP issues embedded in the training pipeline have propagated widely through the open-source ecosystem.
Is DeepSeek distilled from ChatGPT?
OpenAI has alleged — and considers it a terms of service violation — that DeepSeek used outputs from ChatGPT and other OpenAI models as part of its training process. The technical evidence cited includes patterns in DeepSeek’s outputs that are 74.2% similar in writing style to ChatGPT’s responses, a degree of similarity that is statistically difficult to explain without training on OpenAI model outputs. DeepSeek’s published distilled models are described as being distilled from its own DeepSeek-R1 model rather than directly from ChatGPT — the core allegation is that R1 itself was built in part using OpenAI outputs, making every downstream DeepSeek R1 distill Qwen and DeepSeek R1 distill LLaMA 70B variant a downstream product of that alleged extraction.
Is DeepSeek using OpenAI models without permission?
OpenAI’s position, as reported by Bloomberg and AP News in early 2025, is that DeepSeek accessed OpenAI’s models through obfuscated third-party routers to circumvent access restrictions and harvested those outputs to train its own models, violating OpenAI’s terms of service regardless of the underlying IP questions. The practical challenge of enforcing this allegation against a Chinese company that operates primarily outside U.S. jurisdiction means that legal outcomes may depend on policy-level responses — export controls, sanctions, or bilateral agreements — rather than civil litigation alone.
What is the difference between DeepSeek knowledge distillation and DeepSeek model distillation?
DeepSeek knowledge distillation refers specifically to the process of transferring reasoning capabilities from the R1 teacher model to smaller student architectures through synthetic training data — the mechanism by which the DeepSeek R1 distill models inherit R1’s chain-of-thought reasoning. DeepSeek model distillation is the broader term describing the overall pipeline of producing compressed, deployable models from a high-performance parent. In practice, both terms describe the same process; the distinction is mostly one of emphasis — knowledge distillation highlights what is being transferred (learned reasoning patterns), while model distillation highlights the output (a smaller, efficient model).
Protecting Your AI Innovations Before the Next DeepSeek Happens
The DeepSeek distillation controversy has demonstrated one thing clearly: a capable adversary with API access to your AI model can replicate years of your R&D investment in months. For SaaS founders and individual inventors, that risk is not abstract. It is the reason IP strategy can no longer be deferred until after product launch or the next funding round.
The companies that will survive the next phase of AI competition are those that treated their models, training data, and novel architectures as protectable assets from day one — especially as new models appear with capabilities extracted from proprietary systems. Those that didn’t file, didn’t document, and didn’t enforce now face competitors who may be operating on a foundation built from their own work — and who may be directing distillation campaigns at other U.S. frontier labs as you read this.
Andrew Rapacke and the Rapacke Law Group team work specifically with AI founders and tech startups to evaluate what in their model development pipeline is patentable, what qualifies for trade secret protection, and how to structure an IP strategy that holds up as the company scales. According to Rapacke Law Group, the firm’s flat-fee model and RLG Guarantee mean clients know exactly what they’re paying before they commit.
Schedule a free IP Strategy Call today to walk through your current AI assets, identify your distillation exposure, and understand what you can file before a competitor does it first.
For deeper guidance on building defensible IP around AI and software innovations, explore the AI Patent Mastery resource and the Must-Have SaaS Patent Guide 2.0.


